
기말고사 준비로 밀린 포스팅 ^^
1. 문자열 분석
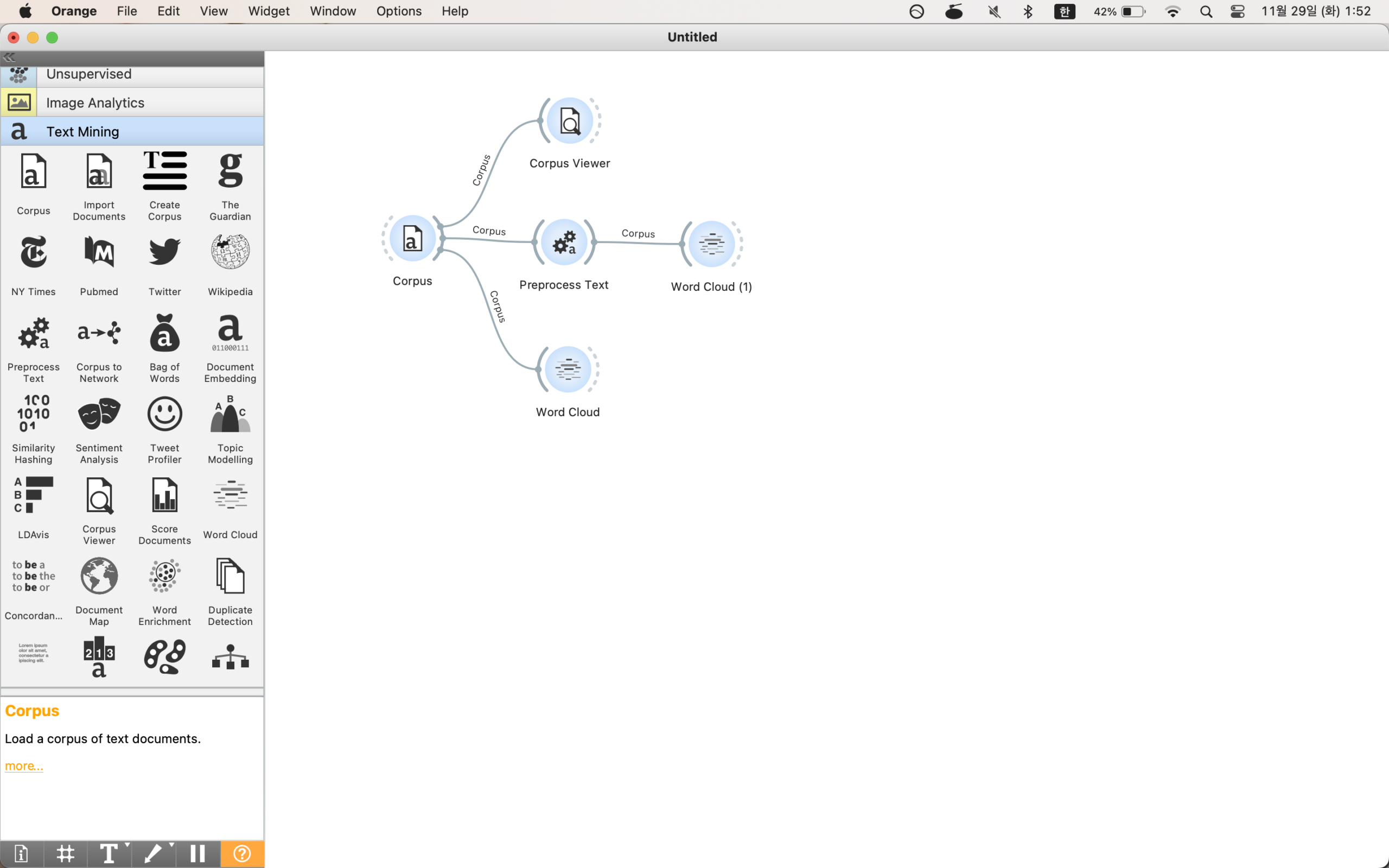
word cloud를 클릭해서 보면 아래와 같은 결과를 볼 수 있다.
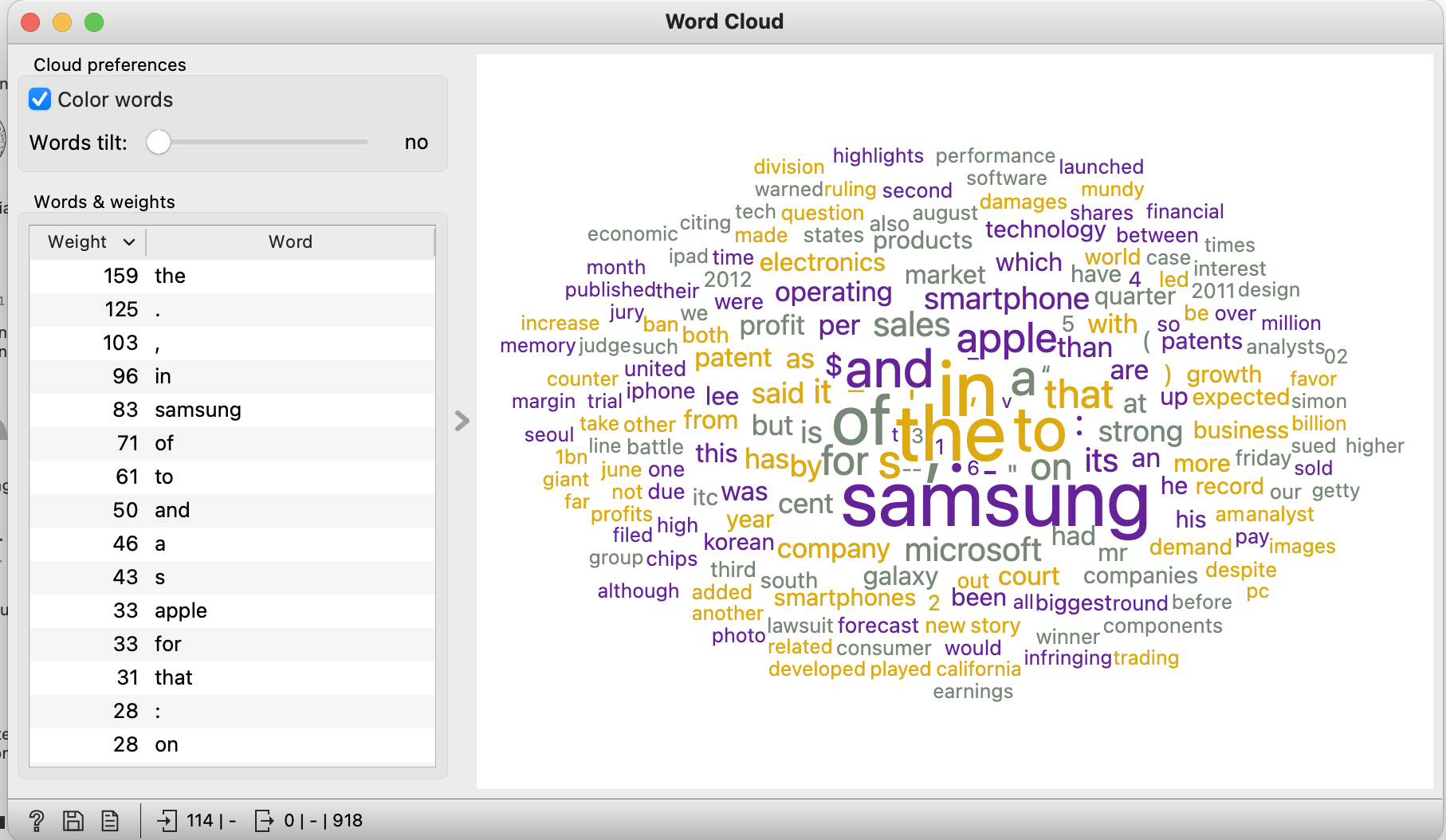 | 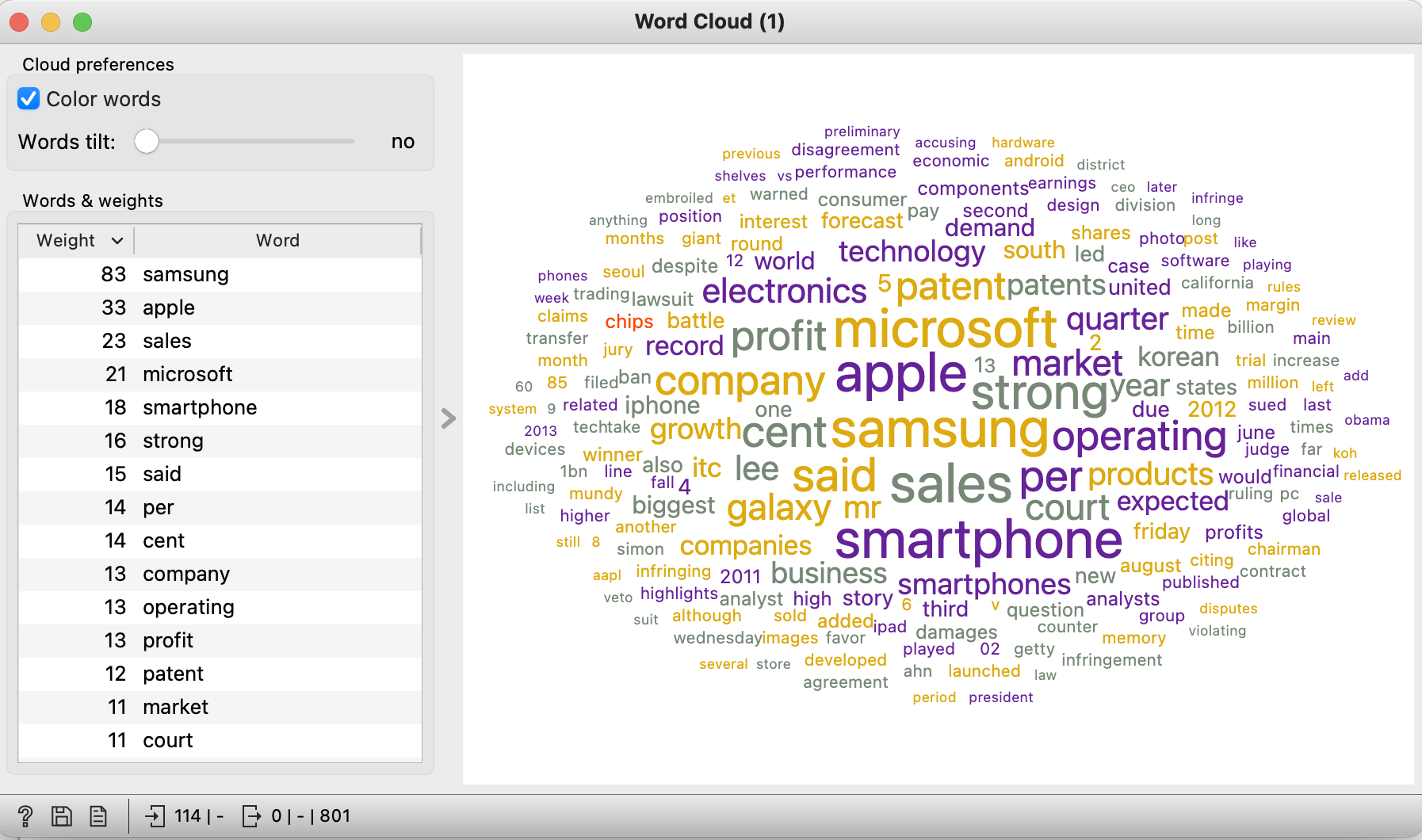 |
preprocess를 한 것과 안 한 것의 차이다.
in, the, to, of와 같은 불필요한 것들을 제거한다.
(이 외에도 preprocess의 역할은 더 다양하다.)
2. 실습_워드클라우드
자기가 스스호 선정한 주제로 직접 위드 클라우드 그려보기.
출처 : https://ftw.usatoday.com/lists/league-of-legends-patch-notes-preseason-2023
롤 프리시즌 패치노트에 관한 기사 중 일부를 이용해서 워드 클라우드를 그려보았다.
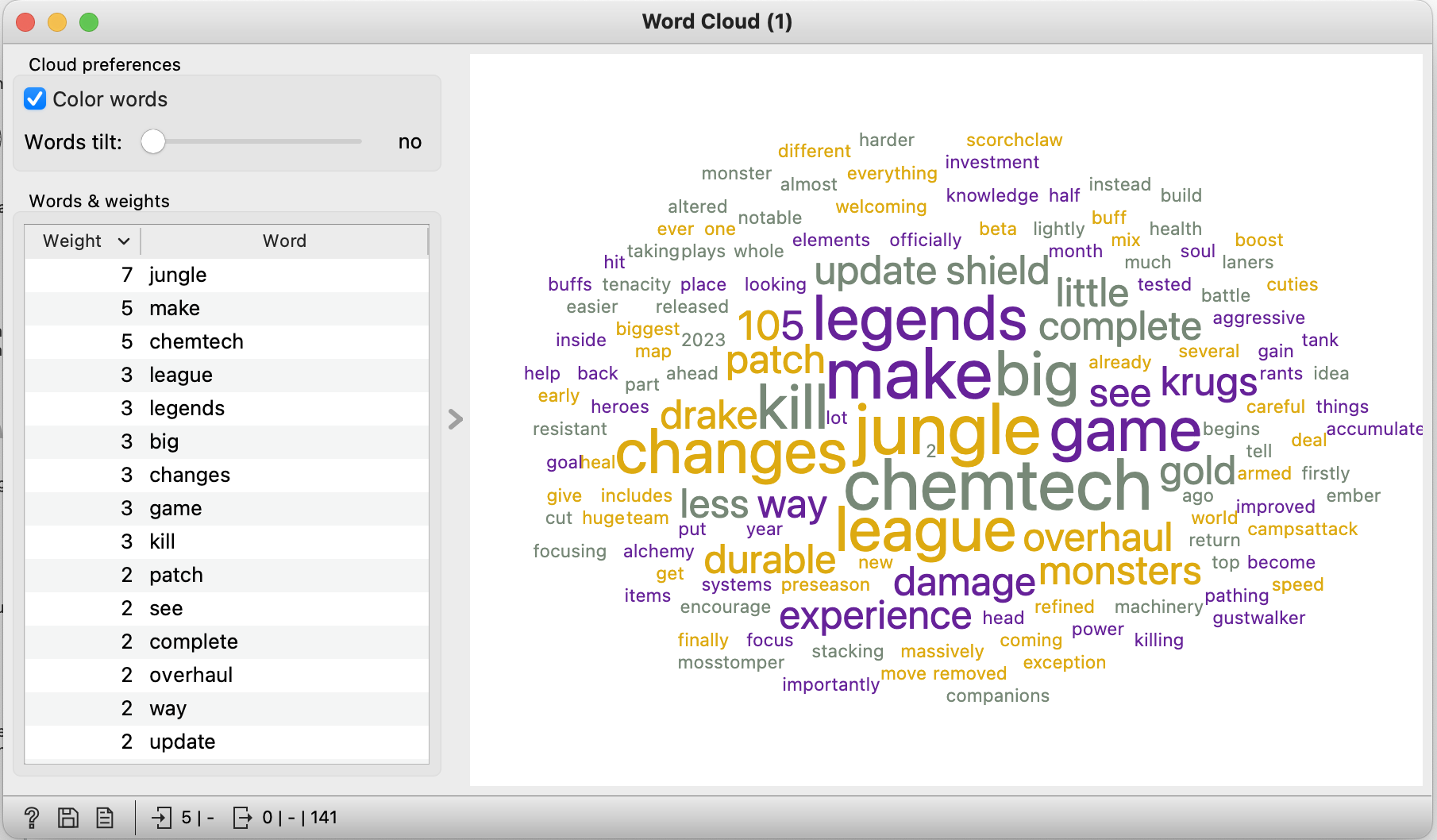
실제로 이번 패치에 관해서 디렉터가 언급한 중요 포인트는 ‘정글 포지션’이었다.
3. 실습_텍스트 비지도 학습
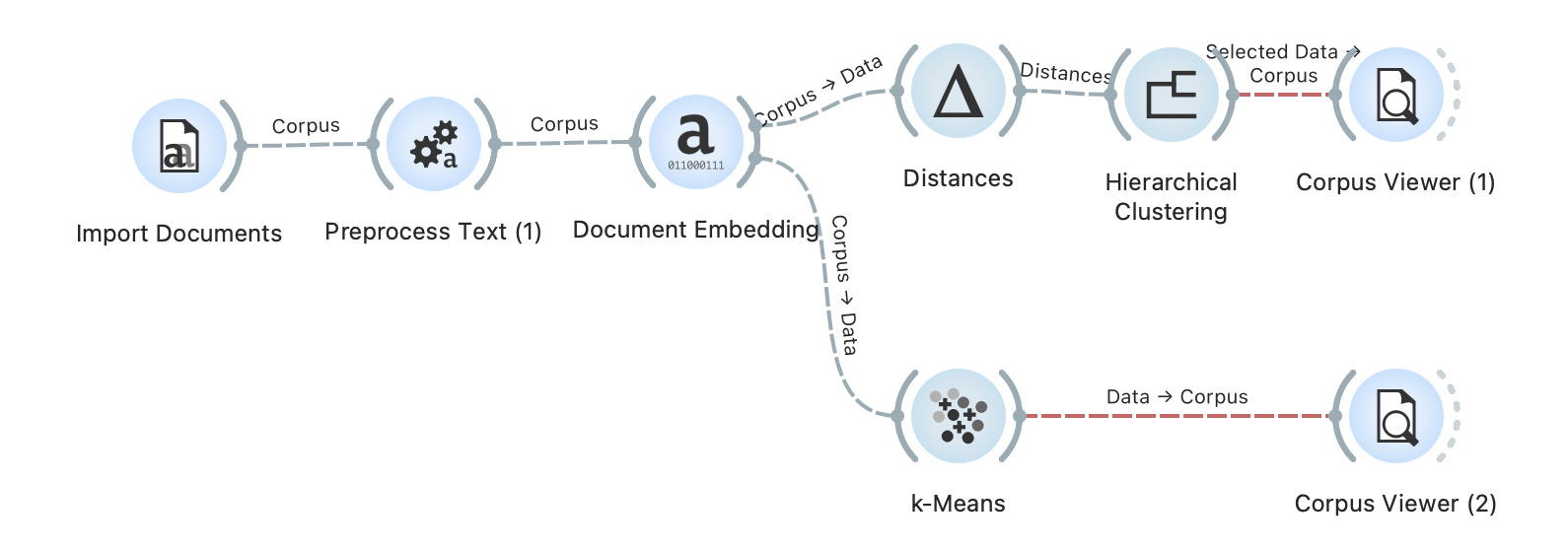
비지도학습이니깐 하나의 폴더에 모든 텍스트가 있음.
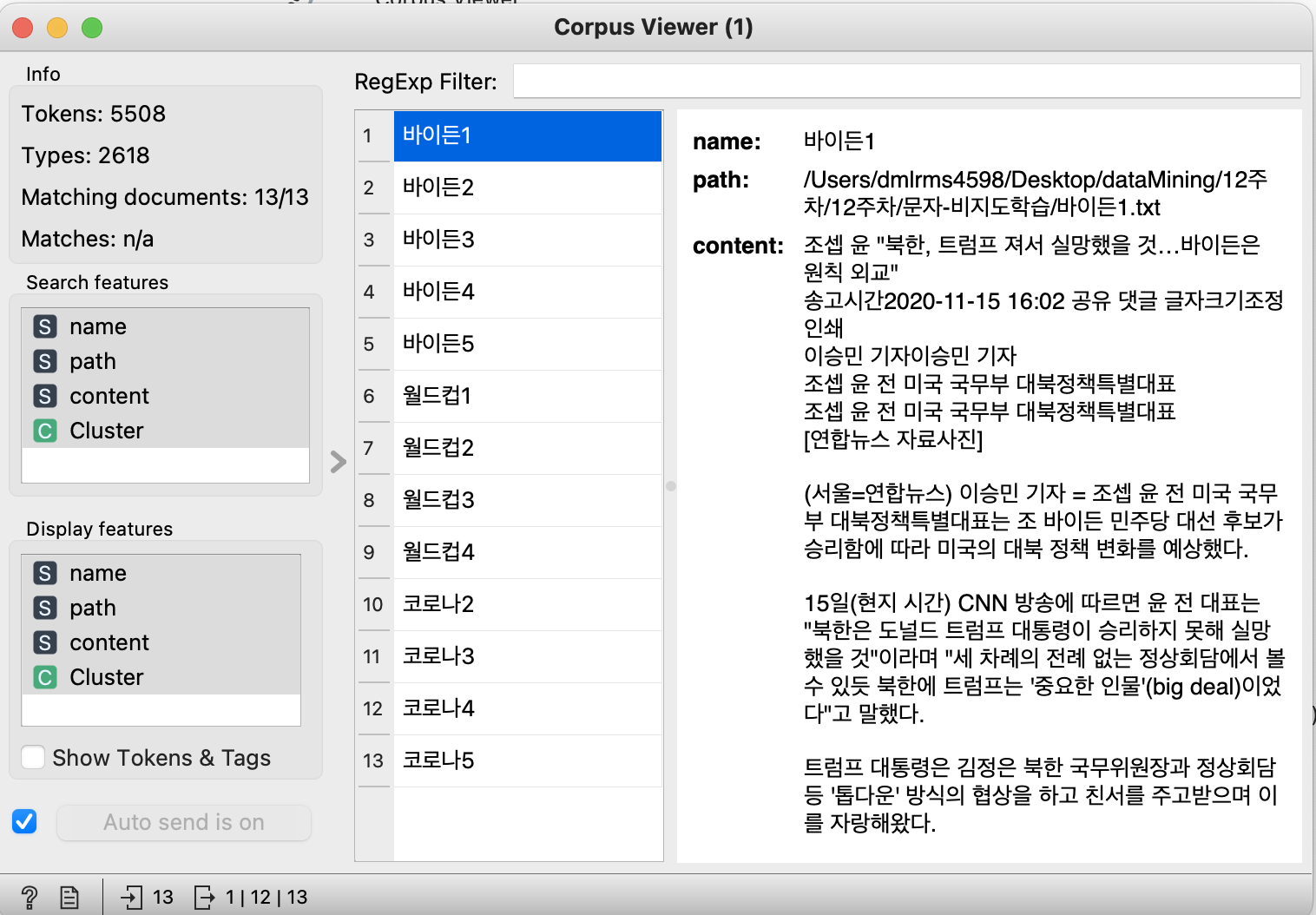
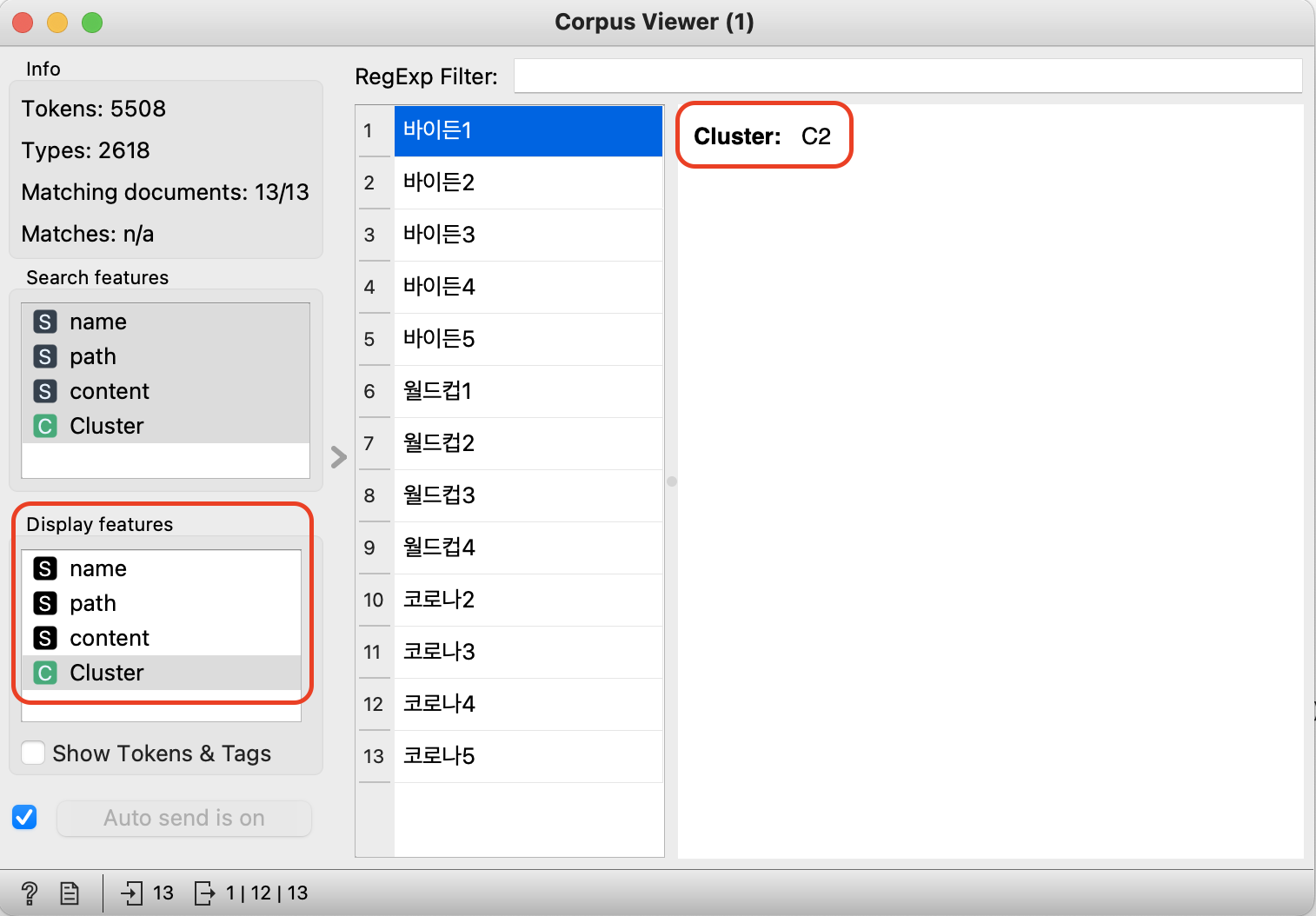
바이든 미국 대통령에 관한 기사는 Cluster 2로 분류되었다.
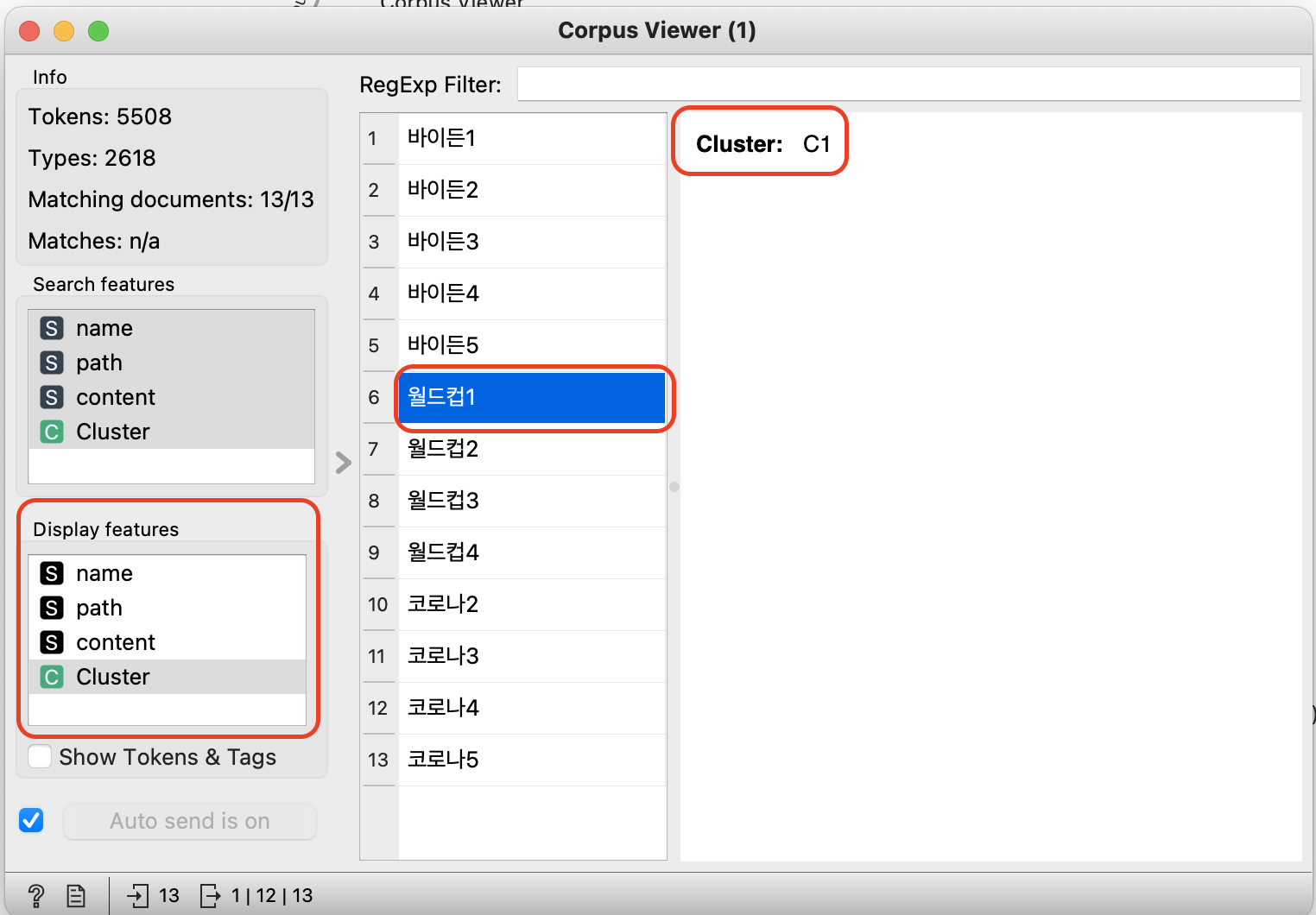
반면에 월드컵 기사는 Cluster 1로 분류되었다.
4. 실습_텍스트 지도학습
몇 가지 주제로 기사를 모아서 학습을 실행하고 학습한 모델을 가지고 ‘예측’하는 실습이다.
날씨, 월드컵, FTX 가상화폐 거래소 파산에 관한 기사를 모았다.
각 주제별로 학습에 사용할 기사 3개, 예측에 사용할 기사 3개를 찾아서 txt 파일로 저장했다.
설명상 test 디렉터리를 같이 두기는 했지만…
실습을 진행하면서는 test 디렉터리는 바깥에 빼두자.
 |
 |
 |
주제별로 서로 다른 디렉터리로 나누면 지도 학습의 label 효과를 얻을 수 있다.
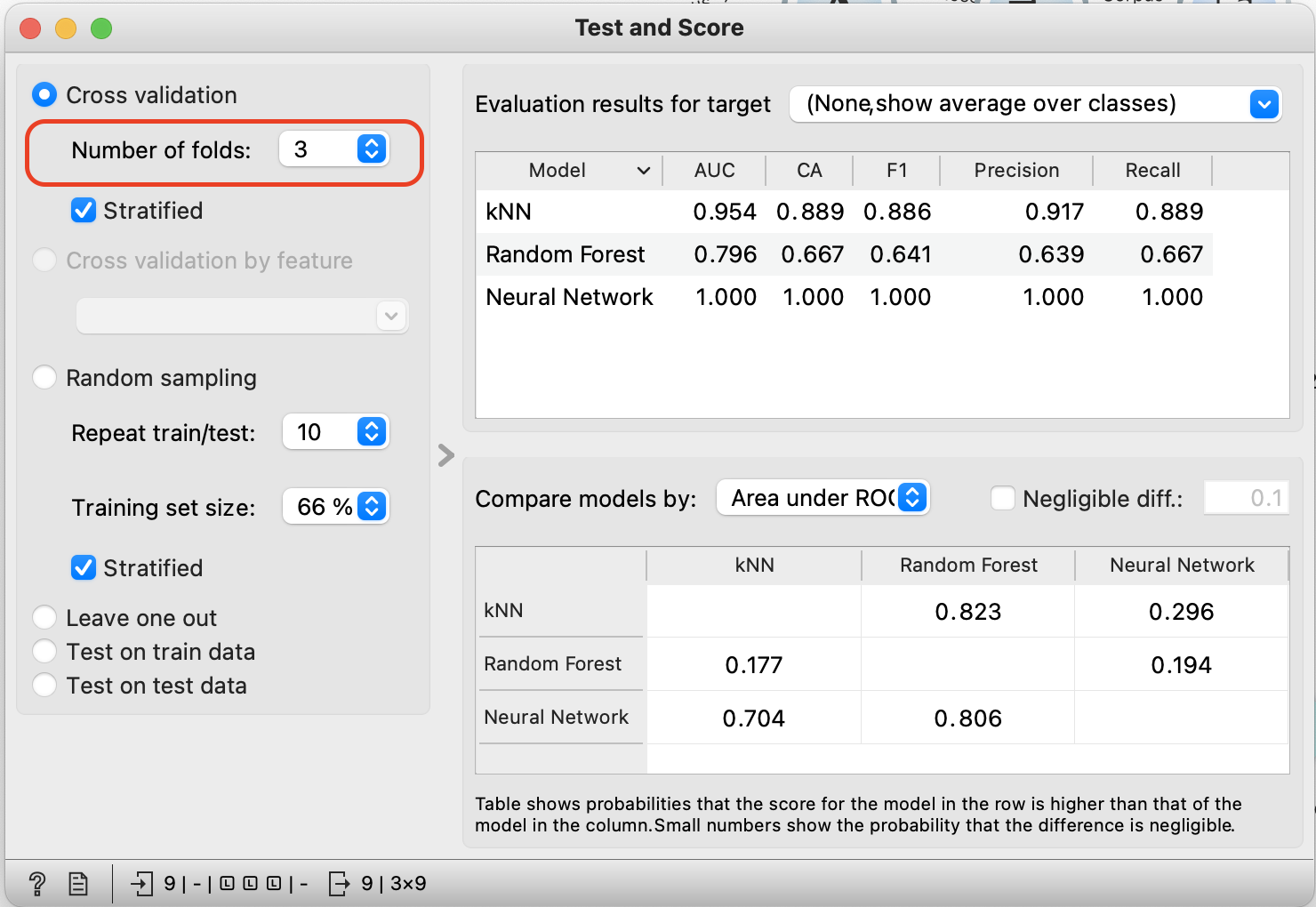
추후에 test and score에서 3가지로 분류한다고 설정해주자.
Predictions에 사용할 데이터는 한 디렉터리에 저장한다.
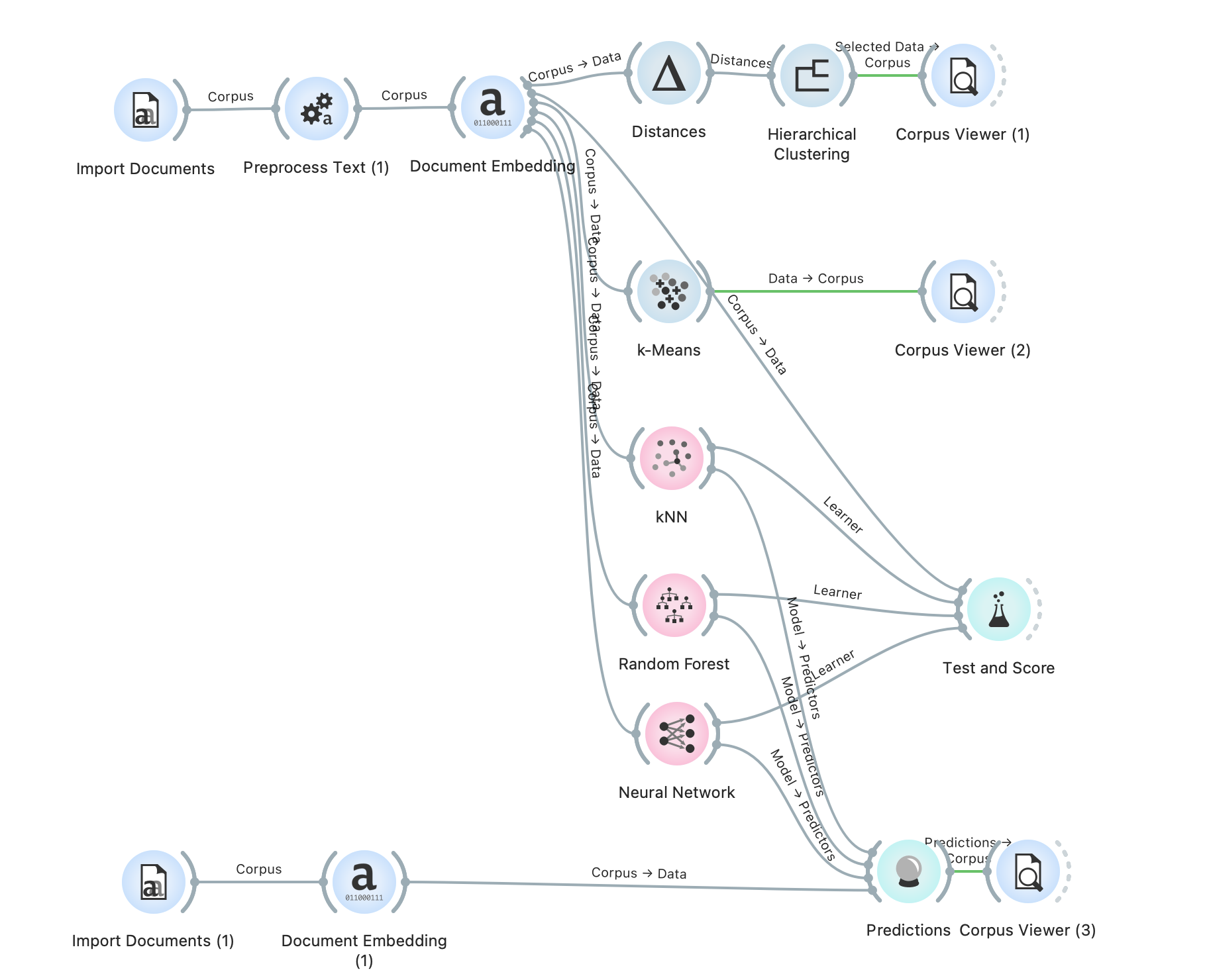
Doc을 Import 해서 전처리 과정을 거친다.
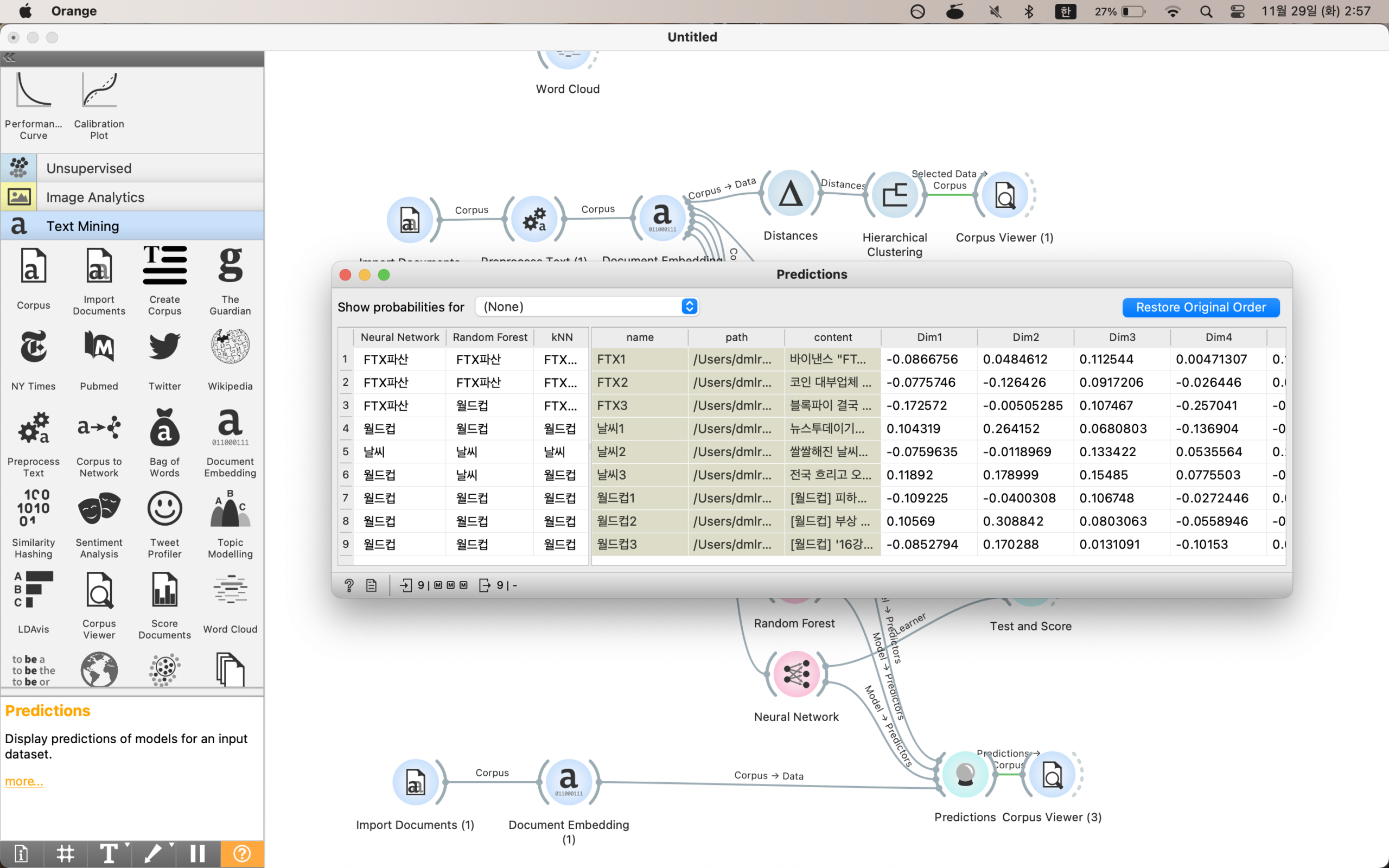
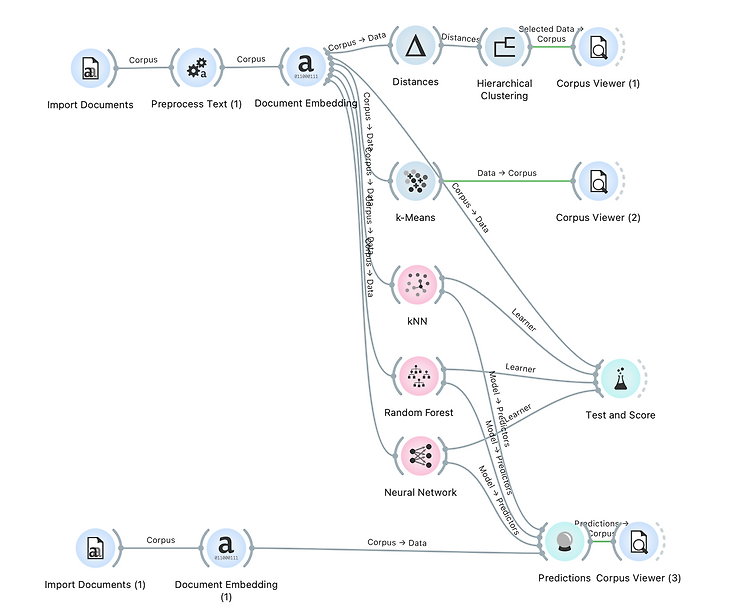
Hierarchical Clustering, K-means, KNN, Random Forest, Neural Network 등 모델에 연결한다.
이후 test 디렉터리에 있는 파일을 import 해서 prediction에 사용한다.